VAEs 같은 심층 생성 모델을 다뤄본 경험이 있다면, KL divergence에 대해 이미 알고 있을 것입니다. 간단히 말해서, 두 확률 분포 사이의 KL divergence는 두 분포가 얼마나 다른지를 측정합니다.
KL Divergence란?
KL divergence(Kullback-Leibler divergence)는 한 확률 분포가 다른 확률 분포와 얼마나 다른지를 측정하는 지표입니다. 전통적으로, 베이지안 이론에서는 어떤 참 분포 P(X)를 근사 분포 Q(X)로 추정하고자 합니다. 이 컨텍스트에서 KL divergence는 근사 분포 Q가 참 분포 P로부터 얼마나 떨어져 있는지를 측정합니다.
KL Divergence(Kullback-Leibler Divergence)를 이해하는 데 필요한 주요 수식들은 다음과 같습니다:
KL Divergence의 정의:

[D_{KL}(P \parallel Q) = \sum_{x \in X} P(x) \log\left(\frac{P(x)}{Q(x)}\right)]
여기서 (P)와 (Q)는 확률 분포, (X)는 사건의 공간을 나타냅니다. 이 수식은 이산 확률 분포에 대한 KL Divergence를 나타냅니다.연속 확률 분포에 대한 KL Divergence:
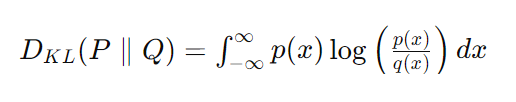
[D_{KL}(P \parallel Q) = \int_{-\infty}^{\infty} p(x) \log\left(\frac{p(x)}{q(x)}\right) dx]
여기서 (p(x))와 (q(x))는 각각 (P)와 (Q)의 확률 밀도 함수입니다.교차 엔트로피(Cross-Entropy):
교차 엔트로피는 KL Divergence를 계산할 때 자주 사용되는 관련 개념입니다.
[H(P, Q) = -\sum_{x} P(x) \log Q(x)]
이산 분포에 대한 교차 엔트로피의 정의입니다. 연속 분포의 경우, 합계 대신 적분을 사용합니다.엔트로피(Entropy):
분포 (P)의 엔트로피는 다음과 같이 정의됩니다.
[H(P) = -\sum_{x} P(x) \log P(x)]
엔트로피는 해당 확률 분포의 불확실성을 측정합니다.KL Divergence와 엔트로피 및 교차 엔트로피의 관계:
[D_{KL}(P \parallel Q) = H(P, Q) - H(P)]
여기서 (H(P, Q))는 교차 엔트로피, (H(P))는 (P)의 엔트로피입니다. 이 관계는 KL Divergence를 교차 엔트로피와 분포의 엔트로피의 차이로 표현합니다.
KL Divergence의 특성
- KL Divergence는 비대칭적입니다: DKL(P||Q) ≠ DKL(Q||P). 결과적으로, 거리 측정법은 아닙니다.
- KL Divergence는 [0, ∞]의 값을 가질 수 있습니다. 특히, P와 Q가 정확히 같은 분포라면 DKL(P||Q) = 0이 됩니다.
- KL divergence가 유한하기 위해서는 P의 지지집합이 Q의 지지집합에 포함되어야 합니다.
목표의 재구성
수학적 조작을 통해, KL divergence의 정의를 다른 양으로 표현할 수 있습니다. 가장 유용한 변형 중 하나는 다음과 같습니다:
DKL(P||Q) = Ex∼P[−logQ(X)] − H(P(X))
여기서, Ex∼P[−logQ(X)]는 P와 Q 사이의 교차 엔트로피이며, H(P(X))는 P의 엔트로피입니다.
감독학습 = Forward KL
감독 학습에서는 참 데이터 분포 p(y|x)에서 샘플된 데이터셋 D를 기반으로 모델 fθ(x)를 학습하여, 근사 분포 qθ(y|x)와 참 데이터 분포 p(y|x) 사이의 발산을 최소화하는 것과 동등합니다. 여기서, forward KL divergence 목표는 최대 우도 추정 문제와 정확히 일치합니다.
강화학습 = Reverse KL
강화학습 문제를 reverse KL 목표를 최소화하는 문제로 보는 것은 강화학습을 확률론적 관점에서 생각하게 합니다. 이 최적화는 최대 엔트로피 강화학습 목표와 정확히 일치합니다.
KL divergence는 머신러닝 전반에 걸쳐 널리 사용되며, KL divergence가 측정하는 내용에 대한 탄탄한 기반 지식은 매우 유용합니다. 통계학에서 KL divergence의 응용에 대해 더 알고 싶다면, 베이지언 추론에 관한 글을 읽어보는 것을 추천합니다. 또한, KL divergence는 정보 이론에서도 풍부한 역사를 가지고 있으며, 이와 관련된 자료를 탐색하는 것도 흥미로울 것입니다. 딥러닝을 사랑한다면, 현재 KL divergence를 사용하는 두 가지 중요한 개념인 VAEs와 정보 병목 현상에 대해 알아보는 것도 좋습니다.
KL Divergence는 머신러닝에서 왜 자주 사용될까요?
KL Divergence는 간단한 분포, 예를 들어 가우시안 분포에 대해서는 폐쇄형으로 쉽게 계산할 수 있습니다. 그러나 비대칭성과 삼각 부등식을 존중하지 않는 등 몇 가지 약점도 가지고 있습니다.
그럼에도 불구하고, KL Divergence는 머신러닝에서 확률 분포 사이의 거리를 계산하는 가장 자연스러운 방법입니다. 정보 이론에서 중요한 방정식으로, 두 확률 분포가 얼마나 가까운지를 비트 단위로 정량화합니다. 이를 상대 엔트로피라고도 하며, 엔트로피와 밀접한 관련이 있습니다.
또한, KL Divergence는 크로스 엔트로피와 밀접한 관련이 있으며, 크로스 엔트로피는 머신러닝에서 SoftMax(또는 시그모이드) 출력 레이어가 있는 손실 함수로 흔히 사용됩니다. 이는 예측 분포를 클래스에 대한 예측 분포로 나타내며, 모델 분포를 실제 레이블과 가능한 한 가깝게 밀어붙이는 것이 목표입니다.
하지만, KL Divergence는 비대칭성을 가지며 이는 때때로 문제가 되기도 합니다. 그러나 대부분의 경우 이러한 비대칭성은 실제 분포를 향해 모델 분포를 추정하려는 목적에 있어서는 결정적이지 않습니다. 또한, KL Divergence와 Wasserstein 지표 같은 다른 통계적 거리 측정치와 비교했을 때, 계산 비용이 낮다는 이점도 있습니다.
이러한 이유들로 KL Divergence는 머신러닝에서 광범위하게 사용됩니다. 그것은 특히 강화 학습과 같은 분야에서 중요한 역할을 하며, 깊은 생성 모델, 예를 들어 VAEs와 같은 분야에서도 중요합니다. 이러한 모든 점들이 KL Divergence가 머신러닝에서 널리 사용되는 이유를 설명해 줍니다.
요약
KL divergence는 머신러닝의 여러 영역에 걸쳐 등장하며, KL divergence가 측정하는 것에 대한 견고한 이해는 매우 유익합니다. 베이지언 추론과 정보 이론에서 KL divergence의 응용에 관심이 있다면, 관련 글을 읽어보시는 것을 권장합니다. 딥러닝 분야에서 VAEs와 정보 병목과 같이 KL divergence를 사용하는 두 가지 주요 개념을 이해하는 것도 중요합니다.
KL divergence는 감독학습과 강화학습을 포함한 다양한 머신러닝 문제에 적용되며, 특정 문제를 해결하기 위한 목표 함수로서의 역할을 합니다. 이러한 개념을 이해하는 것은 머신러닝 모델을 개발하고 최적화하는 데 있어 중요한 기초를 제공합니다. 머신러닝 분야에서 KL divergence의 이론과 응용을 탐구하는 것은 연구자와 개발자 모두에게 필수적인 요소입니다.
Python 예제:
import torch
import numpy as np
from torch import nn
from scipy.stats import entropy
def kl_divergence_calibration(orig_tensor, num_bins=2048, min_val=None, max_val=None):
"""
Calibrates the scale and zero_point for quantizing `orig_tensor` using KL divergence.
Args:
orig_tensor (Tensor): The original, full-precision tensor.
num_bins (int): Number of bins to use for histogram calculation.
min_val (float): Minimum value to consider for histogram (overrides automatic calculation if not None).
max_val (float): Maximum value to consider for histogram (overrides automatic calculation if not None).
Returns:
scale (float): Optimal scale for quantization.
zero_point (int): Optimal zero_point for quantization.
"""
# Calculate histogram of original tensor
if min_val is None or max_val is None:
min_val, max_val = orig_tensor.min(), orig_tensor.max()
hist = torch.histc(orig_tensor, bins=num_bins, min=min_val, max=max_val)
# Generate a tensor of possible scale values (this range might need adjustment)
scale_candidates = torch.linspace(0.01, 1.0, steps=1000)
kl_divergences = []
for scale in scale_candidates:
# Simulate quantization and dequantization
zero_point = 128 # Assuming uint8 quantization
quantized = torch.clamp(torch.round(orig_tensor / scale) + zero_point, 0, 255)
dequantized = (quantized - zero_point) * scale
# Calculate histogram of dequantized tensor
dequant_hist = torch.histc(dequantized, bins=num_bins, min=min_val, max=max_val)
# Calculate KL divergence
kl_div = entropy(hist.numpy(), dequant_hist.numpy())
kl_divergences.append(kl_div)
# Find the scale with the minimum KL divergence
min_kl_index = np.argmin(kl_divergences)
optimal_scale = scale_candidates[min_kl_index].item()
# Calculate optimal zero_point based on optimal_scale (this example uses a simple fixed zero_point)
optimal_zero_point = 128 # Placeholder for an actual calculation
return optimal_scale, optimal_zero_point
# Example usage
orig_tensor = torch.randn(100, 100) # Example tensor
scale, zero_point = kl_divergence_calibration(orig_tensor)
print(f"Optimal scale: {scale}, Optimal zero_point: {zero_point}")'AI-코딩' 카테고리의 다른 글
| Open AI GPT 모델 비교: GPT-3.5 vs GPT-4 vs GPT-4 Turbo (0) | 2024.04.04 |
|---|---|
| 스포티파이 가격 인상, 디지털 엔터테인먼트의 미래를 어떻게 바꿀까? (0) | 2024.04.04 |
| LLM/GPT Comparison (updated 4/3/2024) (0) | 2024.04.03 |
| 테슬라의 도전, 전기차 시장의 미래 (0) | 2024.04.02 |
| Evaluating Tesla's Performance and the EV Market Dynamics (0) | 2024.04.02 |

댓글